Following previously announced plans, NVIDIA said it had opened new original elements of the RUN: AI platform, including the Kai planner.
The planner is a native Kubernetes GPU planning solution, now available under the Apache 2.0 license. Originally developed in the Run platform: AI, Kai Schededulle is now accessible to the community while continuing to be packed and delivered as part of the Nvidia Run platform: AI.
Nvidia said this initiative highlights Nvidia’s commitment to advance both open-source and business infrastructure, promoting an active and collaborative community, encouraging contributions,
Comments and innovation.
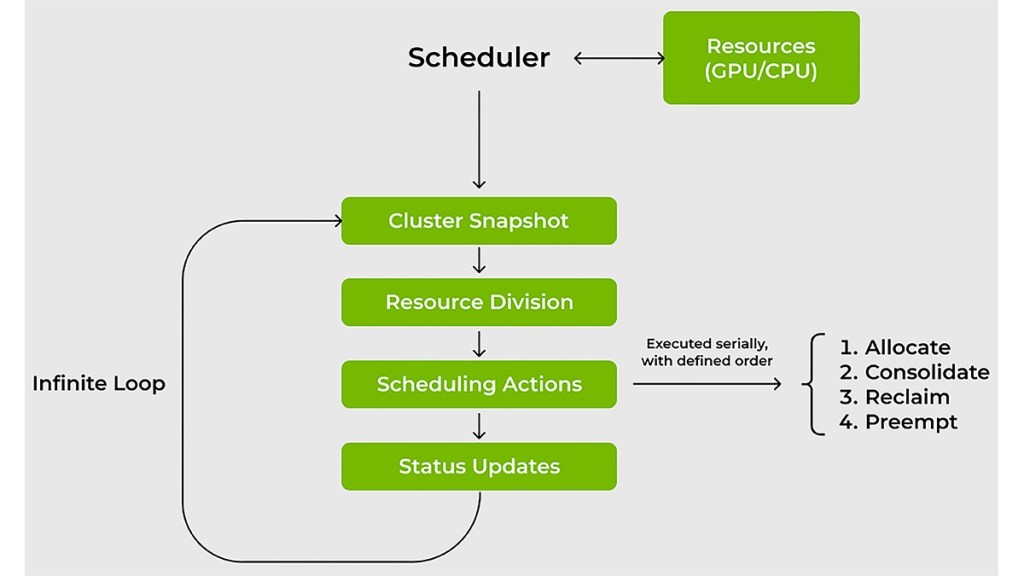
In their article, Ronen Dar and Ekin Karabulut of Nvidia provided an overview of the technical details of Kai Scheduli, highlighting his value for the IT teams and ML and explain the cycle and the planning actions.
Advantages of the Kai planner
The management of workloads on AI on GPUs and CPUs presents a number of challenges that traditional resource planners often do not manage to take up. The planner has been developed to specifically solve these problems: the management of fluctuating GPU requests; Reduced waiting times for access to calculation; Resource guarantees or GPU allocation; And transparently connect the IA tools and frameworks.
Manage fluctuating GPU requests
AI workloads can change quickly. For example, you may need a single GPU for interactive work (for example, for data exploration), then suddenly require several GPUs for distributed training or several experiences. Traditional planners fight with such variability.
The Kai planner continuously recalculates fair sharing values and adjusts quotas and limits in real time, automatically corresponding to current workload requests. This dynamic approach ensures effective GPU allocation without constant manual intervention by administrators.
Reduced waiting time for access to calculation
For ML engineers, time is gasoline. The planner reduces waiting times by combining gang planning, GPU sharing and a hierarchical queue system that allows you to submit lots of jobs, then keep yourself away, confident that the tasks will be launched as soon as the resources are available and in alignment of priorities and equity.
To further optimize the use of resources, even in the face of fluctuating demand, the planner
Employs two effective strategies for GPU and CPU workloads:
Bin-boating and consolidation: maximizes the use of calculation by fighting resources
Fragmentation – Compare smaller tasks in GPU and partially used processors – and addressing
Fragmentation of the node by reallocation of tasks through nodes.
Propagation: uniformly distributes workloads on nodes or GPUs and processors to minimize
Load by node and maximize the availability of resources by workload.
Resource guarantees or GPU allocation
In shared clusters, some researchers guarantee more GPU than necessary at the start of the day to ensure availability throughout. This practice can lead to underused resources, even when other teams still have unused quotas.
Kai Scheduler addresses this by applying resource guarantees. It guarantees that the AI practitioners’ teams receive their allocated GPUs, while dynamically reaches inactive resources to other workloads. This approach prevents resources currency and promotes the overall effectiveness of clusters.
The connection of AI workloads with various AI frames can be intimidating. Traditionally, the teams are faced with a maze of manual configurations to link workloads with tools like Kubeflow, Ray, Argo and the training operator. This complexity delays prototyping.
Kai Scheduler addresses this by presenting an integrated podgroup that automatically detects and connects to these tools and frames – reducing configuration complexity and accelerating development.



